
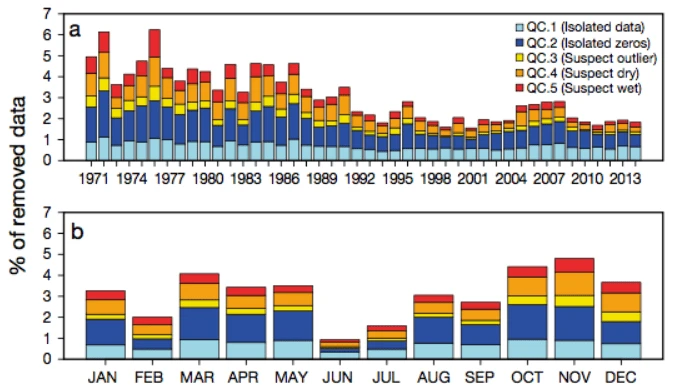
ABSTRACT: This work presents a method for the reconstruction of fragmentary daily precipitation datasets. The method aims to preserve the local and temporal variability characteristic of high-frequency precipitation data, and does not use the time-structure of the data. Based on the precipitation values recorded at closest neighbours during a target day, 2 reference values (RVs) are computed: a binomial prediction (BP) expressing the probability of occurrence of a wet day; and a magnitude prediction (MP), referring to the amount of precipitation. Generalised linear models (GLMs) are used to compute the RVs using the precipitation data (occurrence and magnitude) of the 10 nearest neighbours as the dependent variable, and the geographic information of each station (latitude, longitude, and altitude) as the independent variables. The RVs are then used to (1) apply quality control to the data, flagging suspect records according to 5 predefined criteria; (2) obtain serially complete time series by imputing RVs to missing observations in the original dataset; and (3) create new time series at locations where there were no observations or gridded datasets with even spatial coverage over the study area. The routines used were compiled into an R-package called ‘reddPrec’ (reconstruction of daily data – Precipitation) available to any user. We applied these methods to the complete daily precipitation dataset of the island of Majorca in Spain, spanning the period from 1971-2014.
Spatially based reconstruction of daily precipitation instrumental data series